

USC Institute for Creative Technologies
Departments of Computer Science, Psychology, and Media Arts and Practice
University of Southern California
Affect recognition: a useful or dangerous tool?
Many assume that a person’s emotional state can be accurately inferred by surface cues such as facial expressions and voice quality, or through physiological signals such as skin conductance or heart rate variability. Indeed, this assumption is reflected in many commercial “affect recognition” tools. For example, Table 1 illustrates some of the findings of a recent survey performed by the Association for the Advancement of Affective Computing (AAAC) on how commercial affect recognition is marketed.
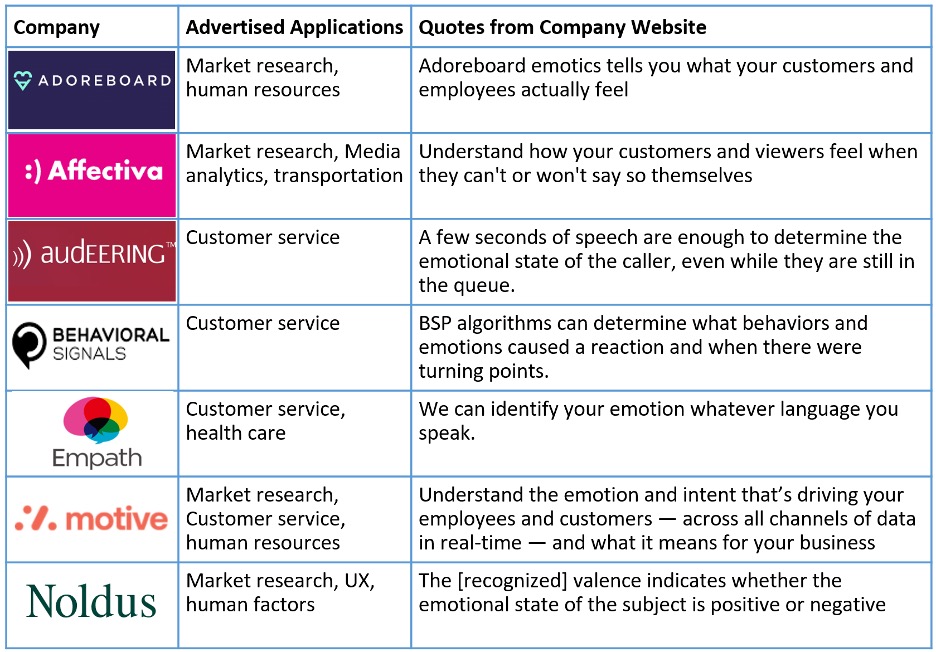
Affective science has long debated the linkages between affective states, emotional expressions and self-reported feelings. The quotes in Table 1 come from products that adopt what I have come to call “context-ignorant” emotion recognition. For example, Affectiva claims to tell you “how your customers and viewers feel” solely from video of a human face without regard to the physical, social, or cultural context in which the face was captured. Digging deeper into their documentation, the company clarifies that the algorithm mimics what third-party observers, also ignorant of the context, would say the face is showing. Early versions of Ekman’s basic emotion theory argued such context-ignorant inferences are meaningful. In this view, emotional state, emotional expressions, and self-reported feelings are tightly linked and essentially act as a single circuit (Ekman, 1992).
The implication is that the recognition of behavior in one component is highly diagnostic of other components, and in particular, that feelings can be readily predicted from surface cues such as facial expressions. However, the emerging consensus within affective science is that components of emotion are loosely connected, and expressions are highly-dependent on the context, shaped by social norms and regulation, and many expressions are completely disconnected from underlying feelings – e.g., arising from deliberate communicative acts or even the articulatory movements required to produce speech (e.g. see Barrett, Adolphs, Marsella, Martinez, & Pollak, 2019; Crivelli & Fridlund, 2018; Scarantino, 2017). Even contemporary proponents of Ekman emphasize the context-specificity of emotional expressions, even when arguing for emotion’s universality (see Cowen et al., 2020). Thus, automatically recognizing emotional state or felt emotions from decontextualized signals is a difficult, if not quixotic enterprise.
This seeming disconnect between the claims of many affect recognition companies and the science of affective signals has raised alarm in some circles. One prominent AI watchdog identified affect recognition as their #1 societal concern, recommending that “regulators should ban the use of affect recognition in important decisions that impact people’s lives and access to opportunities” (Crawford et al., 2019, pg. 6). In fact, I was quoted, misleadingly, as evidence for such a ban (pg. 51). But this reaction also lacks context. For example, given that “affect” encompasses moods and chronic states such as depression and PTSD, a literal interpretation would prevent doctors from using validated scales to identify patients at risk of mental illness (in that such scales constitute a primitive form of affect recognition “technology”). As I will highlight, affective signals can meaningfully inform decision-making as long as appropriate care is taken in their measurement and interpretation.
One of the key problems with these tools comes down to terminology. “Affect recognition” overstates the capabilities of these systems, as most focus on expression recognition. On the other hand, “affect recognition” understates the utility of these methods, as expression contain important information even if this information is disconnected from underlying feelings and emotional state. Unfortunately, such tools rarely come with the appropriate disclaimers or concrete advice on how to avoid their misuse. In this article, I will give a broad overview on how these methods work, the many ways they can yield misleading results, and the emerging engineering advances that address the most common points of failure. These failures broadly fall into two categories: problems in recognizing affective expressions, and problems in understanding what can be concluded from these expressions (even if they have nothing to do with emotion). In illustrating these challenges, I will focus on facial expressions but similar issues arise in other modalities such as affective speech or text analysis.
Challenges facing expression recognition
Most of the algorithms advertised as “emotion recognition” or “affect recognition” are designed to recognize expressions, not “emotion” or “feeling”. These algorithms use machine learning to map from some input (e.g., an image or video of a face) to some label. Some labels are clearly about facial expressions. For example, OpenFace and AFFDEX map an image of a face to a vector of Facial Action Units. The algorithm takes a large database of images that were labeled by trained coders and mimics the skill of these experts. But the majority of these algorithms produce other labels, such as Ekman’s seven basic emotions or other affective or mental states such as frustration, confusion or fatigue. To understand the meaning of these labels, we have to look at the details (which are often, frustratingly, not provided). Many algorithms are trained to recognize prototypical expressions generated by an actor. For example, Emoreader uses a” training database is comprised of 72,800 faces from 3,092 actors.” Other algorithms rely on third-party judgments. For example, Affectiva used trained human coders to look at images and label them for the presence or absence of disgust (McDuff, Kaliouby, Cohn, & Picard, 2015). Either way, these labels are best seen as expressions as the underlying feelings or emotional state is unknown (in the case of third-party observations) or unrelated (in the case of acted expressions).
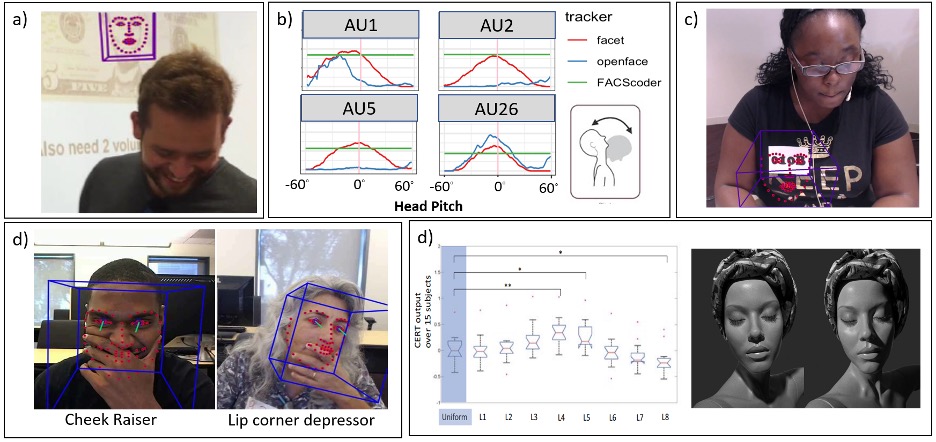
Recognizing expressions is not the same as recognizing feelings or emotional state, but classifying facial signals is still valuable if classified correctly. Unfortunately, the measurement context can systematically bias the output of these methods. Figure 1 illustrates some of common problems we have encountered in our own research based on superficial details of the recording environment or participant appearance. These details include:
- Scene complexity: One of the first steps in expression recognition is to find the face and Figure 1a highlights that face detection can become confused when the scene is complex or other faces lurk in the background. In this case, the face of Abraham Lincoln appears more interesting than the person in the foreground. Automatic expression recognition works best when a person sits alone with a neutral background, but many studies deviate from this ideal, either because of a lack of knowledge of this limitation or other pragmatic concerns. For example, video data collected “in the wild” typically involves high scene complexity. This can undermine the accuracy of results.
- Head orientation: Part of the issue with the image is 1a is that the person is looking down. Indeed, head orientation is a major concern for expression recognition (see Kappas, Hess, Barr, & Kleck, 1994). Many face detectors loose track of the face when the head rotates more than ten or twenty degrees off axis. But perhaps more problematic, small but systematic changes in head orientation can bias the results of an experiment. Figure 1b illustrates how recognition of a prototypical surprise expression (i.e., AU1 + AU2 + AU26) changes as a function of head pitch (the graphs show expert FACS coder ratings contrasted against two expression recognizers). This highlights that the placement of a camera (e.g., above or below a monitor) or even the height of a participant can create confounds in a study (e.g., observed differences in expressions between men or women might simply reflect that men are taller on average).
- Skin tone: Several researchers have highlighted that face and expression recognition algorithms exhibit racial bias. Figure 1c illustrates an example where the face detector is fixated on an apparent white face in this image (the letters “0 1 0” on this black participant’s id number). In our own work, we have found that these effects can introduce systematic biases into machine learning algorithms that use this input. For example, we developed a technique to classify workers as engaged or disengaged with a task based on their expression. Black participants were more frequently misclassified as disengaged workers than white participants.
- Occlusions: People frequently touch their face and this can undermine the accuracy of expression recognition. Figure 1d shows some examples of how these facial occlusions can change what is reported. We discovered these images by looking for cases in one of our corpora where specific action units showed high activation. For example, in the woman on the left, the space between her fingers are misrecognized a mouth. Such effects could systematically bias experimental results. For example, self-touching has been argued to be an indicator of stress (Ekman & Friesen, 1974). If true, automatic findings on the association of facial expressions and stress must control for facial touching.
- Lighting: Photographers and cinematographers have long understood that lighting changes perceptions of emotion. Even before photography, Japanese Noh actors used this effect to convey very different expression from a static mask (Kawai, Miyata, Nishimura, & Okanoya, 2013). Unfortunately, this phenomenon also shapes the output of expression recognition techniques. Figure 1d shows the reported activation of AU4 (brow lowerer) using the FACET commercial expression recognizer under a variety of lighting conditions (Stratou, Ghosh, Debevec, & Morency, 2012). This highlights that some experimental findings on expressions could be influenced by lighting artefacts. For example, studies on the effect of time-of-day on facial expressions might report spurious correlations if video is collected in a room with an open shade.
- Non-expressive sources of facial motion: The face moves for many reasons including the articulatory movements required for speech, chewing, swallowing and breathing. Third-party observers would tend to filter out these movements when judging facial expressions but many algorithms don’t. Most automatic analysis of facial expressions are performed on individual images and an overall expression is calculated by aggregate measures such as mean, max or velocity over some time window. At the level of individual frames, the mouth shape from smiling and the mouth shape from saying the word “cheese” appear identical. As a consequence, an experimental finding that depressed individuals show flattened affect in a study might simply reflect that they spoke less, unless analysis was restricted to areas of non-speech or if the amount of speech was statistically controlled.
Affective computing researchers are well aware of these concerns and engineering solutions are in the works. Facial detection accuracy is quickly advancing as more and more research focuses on collection in the wild. Problems with head orientation are being addressed by training algorithms on 3D data to better account for how the appearance changes when a 3D face is projected on a 2D image (Jeni, Cohn, & Kanade, 2015). Problems with skin tone are often traced to the lack of data collected on minority groups and many of the more egregious problems have now been corrected (Raji & Buolamwini, 2019) though many challenges remain. Researchers are developing “occlusion-aware” facial expression methods that can minimize the impact of self-touching (Li, Zeng, Shan, & Chen, 2019) and algorithms can automatically infer how a scene is illuminated, making it possible to correct for the impact of lighting on facial appearance (Xie, Zheng, Lai, Yuen, & Suen, 2011). Algorithms are also being developed to filter out non-expressive sources of facial motion, such as speech (Kim & Mower Provost, 2014).
Until these methods are perfected, researchers can minimize the impact of these issues by taking care during expression measurement. This can include collecting data in windowless rooms with uncluttered backgrounds and standardized lighting and camera locations. Participants can be cautioned to avoid self-touching. To avoid the impact of head orientation, consider presenting stimuli on a computer screen and avoid secondary tasks that lead people to look away from the screen. For example, studying expressions during team tasks will introduce fewer expression artefacts if the team works on Zoom rather than in-person (as eye contact can be maintained without large head rotations). When these factors cannot be eliminated, confidence in findings can be enhanced by ensuring these factors do not vary systematically with experimental condition. This can be addressed statistically. For example, head orientation or lighting can be measured and controlled for in any analysis.
Challenges facing expression understanding
Assuming we can accurately recognize facial expressions, surely these can support useful inferences. For example, Taco Bell could show customers a video of their new “Loaded Nacho Taco” and predict if people will buy it based on if they smile or show disgust. As illustrated in Table 1, market research is a heavily promoted application of this technology and some research suggests it can be effective. A large study supported by Affectiva showed that expressive reactions to product advertisements can predict if people like an advertisement and, to a somewhat lesser extent, intentions to purchase the product (McDuff et al., 2015). While an important validation of the use of automatic expression recognition, the study also emphasizes the importance of context in shaping these predictions. Rather than using summary statistics (e.g., checking if people smiled more during an ad), expressions were fed, along with several contextual features, into machine learning algorithms. Contextual features included the type of product (e.g., pet care, food, or candy) and country of origin. Ads were also classified by the type of emotions they were designed to evoke (e.g., amusement, inspiration, sentimentality). Findings showed that context mattered. Ad liking was best predicted when focusing on ads designed to be amusing and when the product category and country of origin were used as inputs to the learn algorithm. More broadly, the findings are specific to a certain context: reaction to TV ads by participants from four affluent western countries (US, UK, Germany, France). It remains unclear if the models learned from this collection of videos would generalize to other contexts (e.g., other products, other countries, or videos drawn at a different period in time). It should also be noted that emotion reactions were extremely rare (only 17% of the frames showed an expression). Thus, it is not possible to infer if a specific individual would like the ad or product. Rather, predictions must be made from a panel of members watching the identical video. Using such panels is common in market research but many of the applications in Table 1 claim to provide information about individuals (e.g., identifying that a particular customer is angry), a claim that needs to be taken with some skepticism.
Moving from expression recognition to expression understanding must account for context. Affective science has documented an array of contextual factors that shape the association between emotion, expression and feeling, but these factors are rarely highlighted by the marketing materials of commercial affective recognition products. The social context around an interaction exerts a particularly strong influence:
- Alone vs. Social: The presence of an audience clearly shapes expressions. When alone, the frequency and intensity of expressions tend to be significantly reduced, whereas self-reported feelings appear less impacted by the presence of others, at least for tasks that don’t rely on a social component (e.g., Fridlund, 1991). Even the presence of an experimenter in the room can influence findings and data collection “in-the-wild” rarely event attempts to control this confounding factor.
- Friends vs. strangers: People tend to be more expressive in the presence of friends compared with strangers and some research suggests the match between expressions and feelings is stronger in the presence of friends (Gratch, Cheng, Marsella, & Boberg, 2013; Hess, Banse, & Kappas, 1995). Tracking the relationship between individuals should [?] expression understanding.
- Impression management: In social settings, people are often concerned about politeness or maintaining a good impression. In customer service jobs, employees are paid to convey a particular emotion (Hochschild, 2003). Although some research seeks to distinguish “authentic expressions” from impression management attempts (Ambadar, Cohn, & Reed, 2009), algorithms might benefit more from controlling for impression management demands.
- Co-construction: The above-mentioned effects occur even in the mere presence of others, but many socially situations involve the back-and-forth display of emotion between two or more people. Rather than reflecting an individual’s feelings, expressions may reflect momentary adjustments to expressions displayed by their interaction partner (Parkinson, 2009). For example, Figure 2 illustrates a common pattern in data we’ve collected in competitive games (see Lei & Gratch, 2019). Here a woman conveys sadness after losing a round, which is immediately mimicked by her partner, leading both players to smile. Some expressions may be better understood as analogous to words in a conversation than conveying some underlying emotional state (see also Scarantino, 2017).
- Social power: The power dynamics between individuals shapes what people express. For example, low-power individuals tend to be more expressive and more willing to engage in mimicry than high-power individuals (e.g., Tiedens & Fragale, 2003). Representing or automatically recognizing power relationship (as in Hung, Huang, Friedland, & Gatica-Perez, 2011) could benefit expression understanding.
- Social goals and motives: Expressions often reflect what people are trying to accomplish in a situation (Crivelli & Fridlund, 2018) and these motives will differ across individuals. For example, in a negotiation, some individuals may be focused on material outcomes (winning) whereas others are focused on maintaining the relationship. Thus, the same expression (smile) may reflect quite different meanings across different individuals (de Melo, Carnevale, Read, & Gratch, 2014).

This is not to say that algorithms cannot infer meaningful information about a situation from patterns of facial expressions. As discussed above, algorithms can infer intentions to buy a product with some accuracy from facial reactions to an advertisement. Algorithms have also been shown to detect risk of depression or suicide form expressions produced in a clinical interview (Cummins et al., 2015). The reason these algorithms are successful is that they control for context: i.e., they are trained on data collected in a specific context and applied to similar situations. Algorithms that avoid this care should be viewed with suspicion.
Towards Knowledge-based affect understanding
I have argued that context-ignorant affect recognition is quixotic enterprise, likely doomed to fail. But that is not a problem with the technology. It is a problem with its use and marketing. People don’t make sense of expressions in the absence of context. For example, in one of our recent studies on competitive games, peoples inferences about the other players emotions were better predicted by context than their opponent’s expressions (Hoegen, Gratch, Parkinson, & Shore, 2019). Affect recognition methods are successful when they control for the context. But automated methods could be even more powerful if they explicitly reason about social situations. Although this article has focused on methods that infer emotion from shallow signals (e.g., facial expressions), another thread of affective computing research has focused on how to predict emotion from deep representations of situations. Much of this work is based on appraisal theory. Algorithms reason about how emotions arise from an appraisal of how an individual’s goals are impacted by events (see Marsella, Gratch, & Petta, 2010 for a review). For example, if a person is known to have a goal of winning and they lose, and the situation does not afford opportunities to reverse the loss, we might reasonably conclude they are sad, even in the absence of obvious expressions. Combining these threads (knowledge-based reasoning with expression recognition) could yield even more robust and accurate inferences (see Yongsatianchot & Marsella, 2016 for one example).
In sum, calls to ban affect recognition are misguided and distract attention from the real issues. Like most human innovations, they can provide clear benefits when used appropriately but clear harms through ill-informed use. Companies and researchers have a responsibility to educate consumers on the constraints and limitations of the technology. This is perhaps even more important with affect recognition as everyone feels they are an expert on human emotion. As is clear from Table 1, we still have a long way to go.
References
Ambadar, Z., Cohn, J. F., & Reed, L. I. (2009). All smiles are not created equal: Morphology and timing of smiles perceived as amused, polite, and embarrassed/nervous. Journal of nonverbal behavior, 33(1), 17-34.
Barrett, L. F., Adolphs, R., Marsella, S., Martinez, A. M., & Pollak, S. D. (2019). Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements. Psychological Science in the Public Interest, 20(1), 1-68. doi:10.1177/1529100619832930
Cowen, A. S., Keltner, D., Schroff, F., Jou, B., Adam, H., & Prasad, G. (2020). Sixteen facial expressions occur in similar contexts worldwide. Nature. doi:10.1038/s41586-020-3037-7
Crawford, K., Dobbe, R., Dryer, T., Fried, G., Green, B., Kaziunas, E., . . . Sánchez, A. N. (2019). AI now 2019 report. New York, NY: AI Now Institute.
Crivelli, C., & Fridlund, A. J. (2018). Facial Displays Are Tools for Social Influence. Trends in Cognitive Sciences, 22(5), 388-399. doi:https://doi.org/10.1016/j.tics.2018.02.006
Cummins, N., Scherer, S., Krajewski, J., Schnieder, S., Epps, J., & Quatieri, T. F. (2015). A review of depression and suicide risk assessment using speech analysis. Speech Communication, 71, 10-49. doi:https://doi.org/10.1016/j.specom.2015.03.004
de Melo, C., Carnevale, P. J., Read, S. J., & Gratch, J. (2014). Reading people’s minds from emotion expressions in interdependent decision making. Journal of Personality and Social Psychology, 106(1), 73-88. doi:10.1037/a0034251
Ekman, P. (1992). An argument for basic emotions. Cognition and Emotion, 6(3-4), 169-200.
Ekman, P., & Friesen, W. V. (1974). Nonverbal behavior and psychopathology. The psychology of depression: Contemporary theory and research, 3-31.
Fridlund, A. J. (1991). Sociality of social smiling: Potentiation by an implicit audience. Journal of Personality and Social Psychology, 60, 229-240.
Gratch, J., Cheng, L., Marsella, S., & Boberg, J. (2013). Felt emotion and social context determine the intensity of smiles in a competitive video game. Paper presented at the 10th IEEE International Conference on Automatic Face and Gesture Recognition, Shanghai, China.
Hess, U., Banse, R., & Kappas, A. (1995). The intensity of facial expression is determined by underlying affective state and social situation. Journal of Personality and Social Psychology, 69(2), 280-288. doi:10.1037/0022-3514.69.2.280
Hochschild, A. R. (2003). The managed heart: Commercialization of human feeling: Univ of California Press.
Hoegen, R., Gratch, J., Parkinson, B., & Shore, D. (2019). Signals of Emotion Regulation in a Social Dilemma: Detection from Face and Context. Paper presented at the 8th International Conference on. Affective Computing & Intelligent Interaction Cambridge, UK.
Hung, H., Huang, Y., Friedland, G., & Gatica-Perez, D. (2011). Estimating Dominance in Multi-Party Meetings Using Speaker Diarization. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 847-860. doi:10.1109/TASL.2010.2066267
Jeni, L. A., Cohn, J. F., & Kanade, T. (2015, 4-8 May 2015). Dense 3D face alignment from 2D videos in real-time. Paper presented at the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG).
Kappas, A., Hess, U., Barr, C. L., & Kleck, R. E. (1994). Angle of regard: The effect of vertical viewing angle on the perception of facial expressions. Journal of nonverbal behavior, 18(4), 263-280. doi:10.1007/bf02172289
Kawai, N., Miyata, H., Nishimura, R., & Okanoya, K. (2013). Shadows alter facial expressions of Noh masks. PLoS One, 8(8), e71389.
Kim, Y., & Mower Provost, E. (2014). Say cheese vs. smile: Reducing speech-related variability for facial emotion recognition. Paper presented at the Proceedings of the 22nd ACM international conference on Multimedia.
Lei, S., & Gratch, J. (2019, 3-6 Sept. 2019). Smiles Signal Surprise in a Social Dilemma. Paper presented at the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII).
Li, Y., Zeng, J., Shan, S., & Chen, X. (2019). Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism. IEEE Transactions on Image Processing, 28(5), 2439-2450. doi:10.1109/TIP.2018.2886767
Marsella, S., Gratch, J., & Petta, P. (2010). Computational Models of Emotion. In K. R. Scherer, T. Bänziger, & E. Roesch (Eds.), A blueprint for affective computing: A sourcebook and manual (pp. 21-46). New York: Oxford University Press.
McDuff, D., Kaliouby, R. E., Cohn, J. F., & Picard, R. W. (2015). Predicting Ad Liking and Purchase Intent: Large-Scale Analysis of Facial Responses to Ads. IEEE Transactions on Affective Computing, 6(3), 223-235. doi:10.1109/TAFFC.2014.2384198
Parkinson, B. (2009). What holds emotions together? Meaning and response coordination. Cognitive Systems Research, 10, 31-47.
Raji, I. D., & Buolamwini, J. (2019). Actionable Auditing: Investigating the Impact of Publicly Naming Biased Performance Results of Commercial AI Products. Paper presented at the Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA. https://doi.org/10.1145/3306618.3314244
Scarantino, A. (2017). How to Do Things with Emotional Expressions: The Theory of Affective Pragmatics. Psychological Inquiry, 28(2-3), 165-185. doi:10.1080/1047840X.2017.1328951
Stratou, G., Ghosh, A., Debevec, P., & Morency, L.-P. (2012). Exploring the effect of illumination on automatic expression recognition using the ICT-3DRFE database. Image and Vision Computing, 30(10), 728-737. doi:https://doi.org/10.1016/j.imavis.2012.02.001
Tiedens, L. Z., & Fragale, A. R. (2003). Power moves: Complementarity in dominant and submissive nonverbal behavior. Journal of Personality and Social Psychology, 84(3), 558-568.
Xie, X., Zheng, W., Lai, J., Yuen, P. C., & Suen, C. Y. (2011). Normalization of Face Illumination Based on Large-and Small-Scale Features. IEEE Transactions on Image Processing, 20(7), 1807-1821. doi:10.1109/TIP.2010.2097270
Yongsatianchot, N., & Marsella, S. (2016). Integrating Model-Based Prediction and Facial Expressions in the Perception of Emotion. In B. Steunebrink, P. Wang, & B. Goertzel (Eds.), Artificial General Intelligence: 9th International Conference, AGI 2016, New York, NY, USA, July 16-19, 2016, Proceedings (pp. 234-243). Cham: Springer International Publishing.
This article is based on a recent webinar presented at ISRE. This article benefited from contributions from USC’s Affective Computing Group but especially Su Lei and Kelsie Lam



